VisFactor Leaderboard
Results
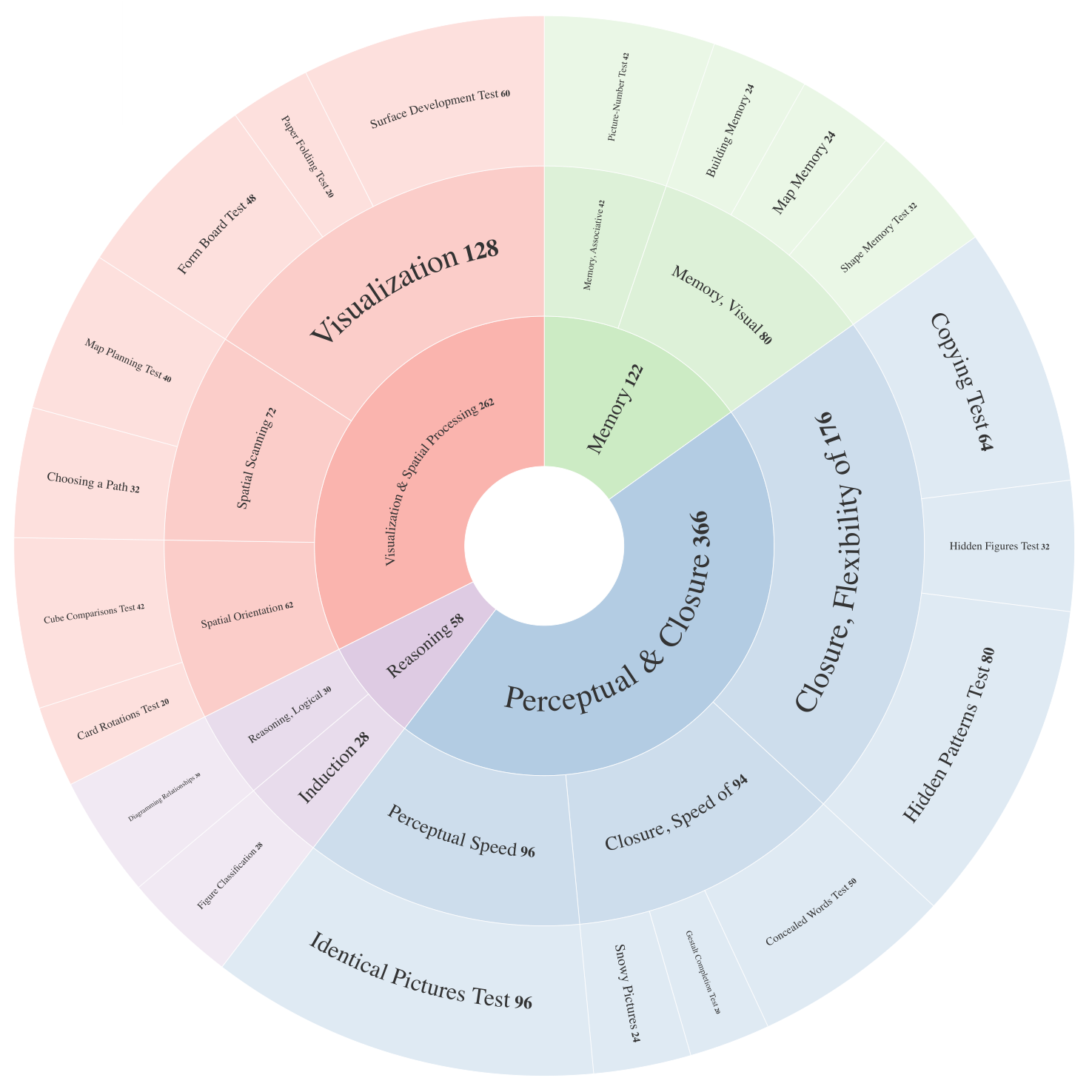
VisFactor digitizes 20 vision-centric subtests from the Factor-Referenced Cognitive Test (FRCT) battery. Select a domain to filter the leaderboard, or view overall results across all subtests. Click any column header to sort.
Framework
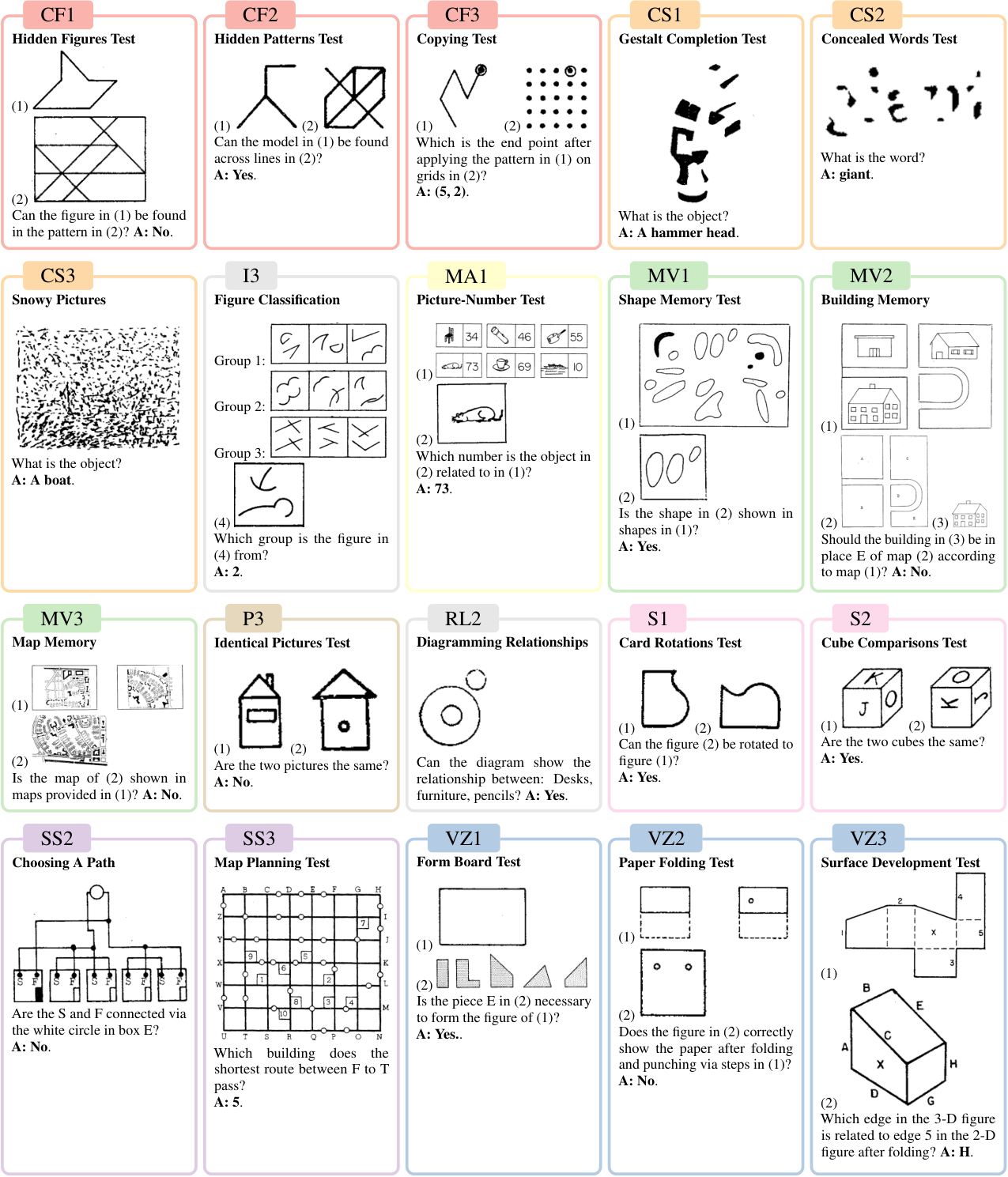
Each FRCT subtest is digitized into a unified vision-to-text format while preserving its intended cognitive factor.
Comparison with Existing Benchmarks
The following table compares VisFactor with prior vision-centric evaluation benchmarks, highlighting psychological grounding, automatic generation, difficulty control, rigorous measurement, image type, and task coverage. Click any column header to sort.
| Benchmarks | #T | #Q | P | G | D | M | I | PR | BM | MM | RT | MZ | PZ |
|---|
BibTeX
If you find our paper & tool useful, you are welcome to cite us using:
@article{huang2025visfactor,
title={Human Cognitive Benchmarks Reveal Foundational Visual Gaps in MLLMs},
author={Huang, Jen-Tse and Dai, Dasen and Huang, Jen-Yuan and Yuan, Youliang and Liu, Xiaoyuan and Wang, Wenxuan and Jiao, Wenxiang and He, Pinjia and Tu, Zhaopeng and Duan, Haodong},
journal={arXiv preprint arXiv:2502.16435},
year={2025}
}More Leaderboards
Explore more excellent benchmarks and leaderboards from ARISE Lab:
- EmotionBench LeaderboardNeurIPS'24 Poster
- PsychoBench LeaderboardICLR'24 Oral
- GAMA-Bench LeaderboardICLR'25 Poster
- CodeCrash LeaderboardNeurIPS'25 Poster